导语
在日常开发中,我们经常会遇到大文件上传的需求,比如视频上传、文档备份等场景。普通的单次上传方式在面对数百MB甚至数GB的文件时会遇到诸多问题:请求超时、内存占用过高、网络中断后需要重新上传等。
本文将深入讲解大文件上传的核心解决方案,包括分片上传、断点续传和秒传三大核心功能,并提供完整的代码实现。
一、大文件上传核心概念
1.1 什么是分片上传
分片上传的原理是将大文件切割成多个小块(Chunk),每个小块单独发送请求到服务端,服务端接收并保存所有分片后再合并成完整的文件。
分片上传的优势:
- 支持断点续传:网络中断后,只需上传未完成的分片
- 并行上传:多个分片可以并行传输,提高上传速度
- 减少内存占用:分片处理,不需要一次性加载整个文件到内存
1.2 断点续传原理
断点续传的核心是记录已上传的分片信息。客户端首先询问服务端文件的上传状态,服务端返回已上传的分片列表,客户端只需上传剩余分片。
1.3 秒传原理
秒传是断点续传的特例。当服务端检测到相同文件已存在时,直接返回成功,无需真正上传文件。实现秒传的关键是文件唯一标识——通过 Hash 算法(如 MD5)计算文件的指纹。
二、前置知识
2.1 File 对象
File 对象是特殊类型的 Blob,包含文件的基本信息:
| 属性 |
描述 |
File.name |
文件名 |
File.size |
文件大小(字节) |
File.type |
文件 MIME 类型 |
File.lastModified |
最后修改时间 |
2.2 Blob 与分片
使用 Blob.slice() 方法可以对文件进行分片:
const blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;
const chunk = blobSlice.call(file, start, end);
|
2.3 FileReader 读取文件
const fileReader = new FileReader();
fileReader.readAsArrayBuffer(blob);
fileReader.onload = (e) => {
console.log(e.target.result);
};
|
大文件上传必须使用 multipart/form-data 格式:
const formData = new FormData();
formData.append('chunk', new Blob([chunkData]));
formData.append('index', 1);
formData.append('fileHash', 'xxx');
|
三、完整实现方案
3.1 前端实现
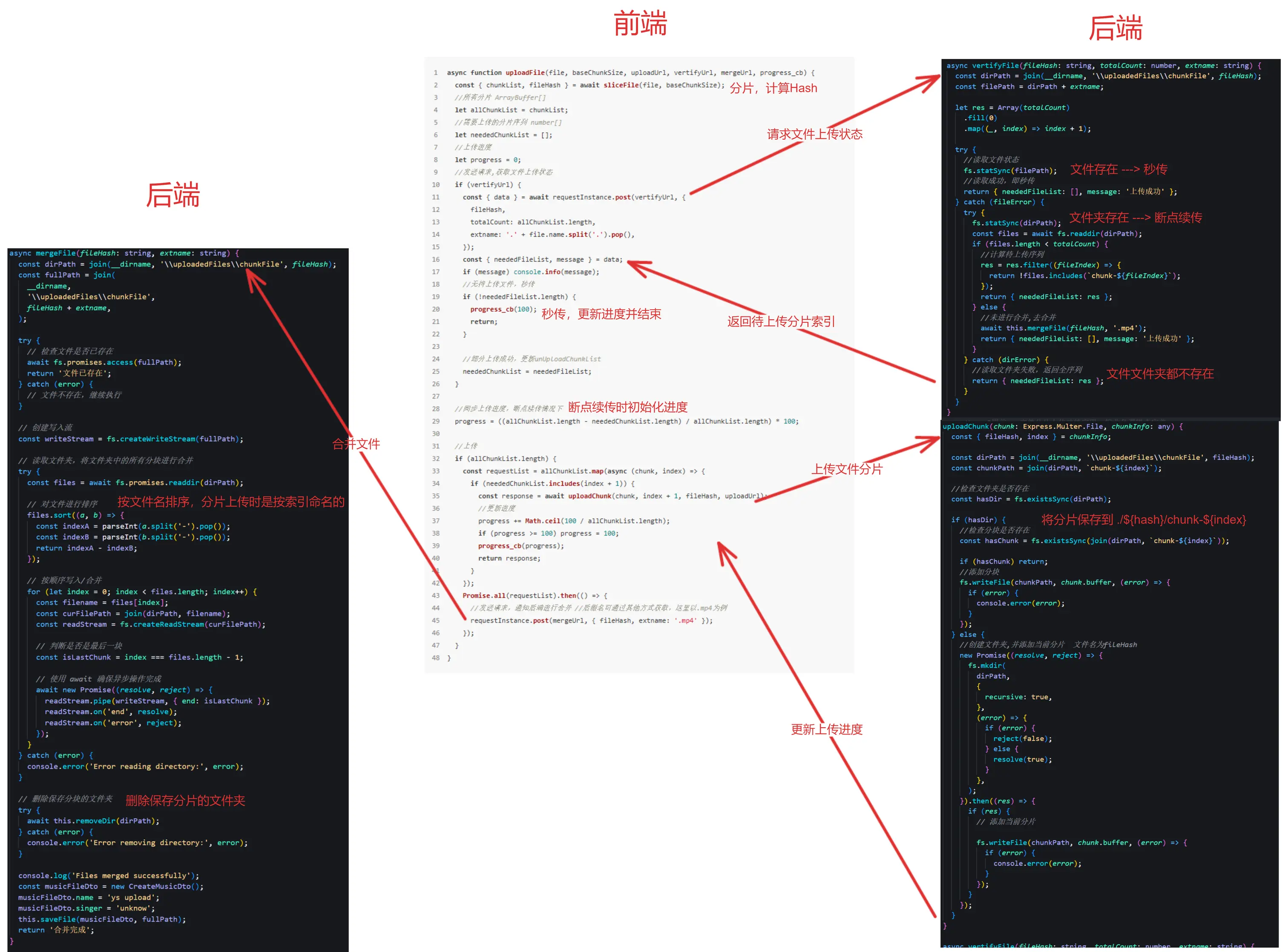
文件分片与 Hash 计算
import SparkMD5 from 'spark-md5';
async function sliceFile(targetFile, baseChunkSize = 1) {
return new Promise((resolve, reject) => {
const blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;
const chunkSize = baseChunkSize * 1024 * 1024;
const targetChunkCount = Math.ceil(targetFile.size / chunkSize);
let currentChunkCount = 0;
const chunkList = [];
const spark = new SparkMD5.ArrayBuffer();
const fileReader = new FileReader();
fileReader.onload = (e) => {
const curChunk = e.target.result;
spark.append(curChunk);
currentChunkCount++;
chunkList.push(curChunk);
if (currentChunkCount >= targetChunkCount) {
const fileHash = spark.end();
resolve({ chunkList, fileHash });
} else {
loadNext();
}
};
fileReader.onerror = () => reject(null);
const loadNext = () => {
const start = chunkSize * currentChunkCount;
const end = Math.min(start + chunkSize, targetFile.size);
fileReader.readAsArrayBuffer(blobSlice.call(targetFile, start, end));
};
loadNext();
});
}
|
分片上传入口
async function uploadFile(file, baseChunkSize, uploadUrl, verifyUrl, mergeUrl, progressCallback) {
const { chunkList, fileHash } = await sliceFile(file, baseChunkSize);
let neededChunkList = [];
let progress = 0;
if (verifyUrl) {
const { data } = await requestInstance.post(verifyUrl, {
fileHash,
totalCount: chunkList.length,
extname: '.' + file.name.split('.').pop(),
});
const { neededFileList, message } = data;
if (!neededFileList.length) {
progressCallback(100);
return;
}
neededChunkList = neededFileList;
}
progress = ((chunkList.length - neededChunkList.length) / chunkList.length) * 100;
if (chunkList.length) {
const requestList = chunkList.map(async (chunk, index) => {
if (neededChunkList.includes(index + 1)) {
await uploadChunk(chunk, index + 1, fileHash, uploadUrl);
progress += Math.ceil(100 / chunkList.length);
if (progress >= 100) progress = 100;
progressCallback(progress);
}
});
Promise.all(requestList).then(() => {
requestInstance.post(mergeUrl, {
fileHash,
extname: '.mp4'
});
});
}
}
async function uploadChunk(chunk, index, fileHash, uploadUrl) {
const formData = new FormData();
formData.append('chunk', new Blob([chunk]));
formData.append('index', index);
formData.append('fileHash', fileHash);
return requestInstance.post(uploadUrl, formData);
}
|
3.2 后端 Node.js 实现
接收分片
const fs = require('fs');
const path = require('path');
uploadChunk(chunk, chunkInfo) {
const { fileHash, index } = chunkInfo;
const dirPath = path.join(__dirname, 'uploadedFiles/chunkFile', fileHash);
const chunkPath = path.join(dirPath, `chunk-${index}`);
if (!fs.existsSync(dirPath)) {
fs.mkdirSync(dirPath, { recursive: true });
}
if (fs.existsSync(chunkPath)) {
return;
}
fs.writeFileSync(chunkPath, chunk.buffer);
}
|
验证文件状态(断点续传/秒传)
async function verifyFile(fileHash, totalCount, extname) {
const dirPath = path.join(__dirname, 'uploadedFiles/chunkFile', fileHash);
const filePath = path.join(dirPath, fileHash + extname);
let res = Array(totalCount).fill(0).map((_, index) => index + 1);
try {
fs.statSync(filePath);
return { neededFileList: [], message: '上传成功(秒传)' };
} catch (fileError) {
try {
const files = fs.readdirSync(dirPath);
if (files.length < totalCount) {
res = res.filter(fileIndex => {
return !files.includes(`chunk-${fileIndex}`);
});
return { neededFileList: res };
} else {
await this.mergeFile(fileHash, extname);
return { neededFileList: [], message: '上传成功' };
}
} catch (dirError) {
return { neededFileList: res };
}
}
}
|
合并分片
async function mergeFile(fileHash, extname) {
const dirPath = path.join(__dirname, 'uploadedFiles/chunkFile', fileHash);
const fullPath = path.join(dirPath, fileHash + extname);
const writeStream = fs.createWriteStream(fullPath);
let files = fs.readdirSync(dirPath);
files.sort((a, b) => {
const indexA = parseInt(a.split('-').pop());
const indexB = parseInt(b.split('-').pop());
return indexA - indexB;
});
for (const filename of files) {
const curFilePath = path.join(dirPath, filename);
const readStream = fs.createReadStream(curFilePath);
await new Promise((resolve, reject) => {
readStream.pipe(writeStream, { end: false });
readStream.on('end', resolve);
readStream.on('error', reject);
});
}
writeStream.end();
fs.rmdirSync(dirPath, { recursive: true });
return '合并完成';
}
|
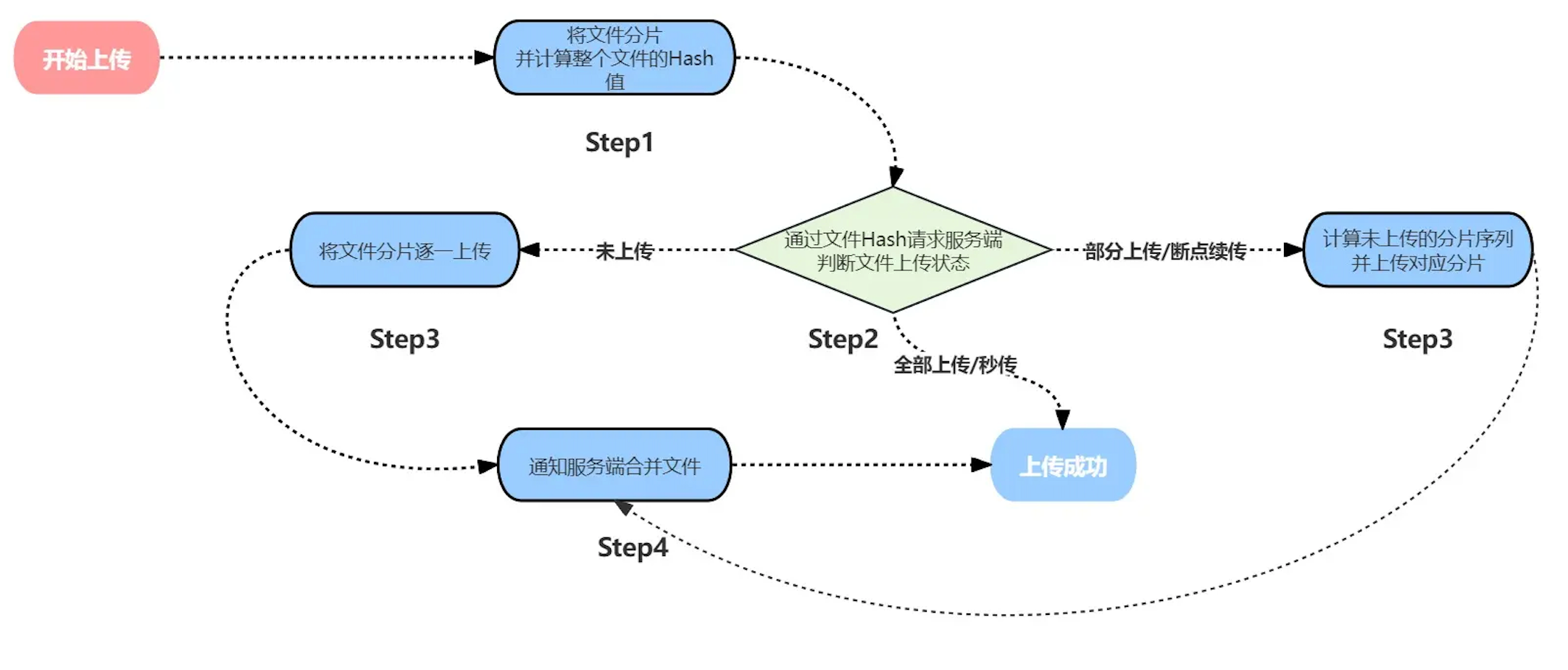
四、上传流程图
整个上传流程如下:
1. 选择文件 → 客户端分片 + 计算 Hash
2. 发送验证请求 → 服务端返回上传状态
3. 根据状态处理:
- 文件已存在 → 秒传成功
- 部分分片存在 → 断点续传(上传剩余分片)
- 文件不存在 → 上传所有分片
4. 全部上传完成后 → 通知服务端合并
|
五、性能优化
5.1 Web Worker 优化
当文件非常大时,Hash 计算会占用大量主线程资源,导致页面卡顿。使用 Web Worker 可以在后台线程中执行计算,不影响用户交互。
async function uploadFile(file, baseChunkSize, ...) {
const worker = new Worker(new URL('./sliceFileWorker.js', import.meta.url), {
type: 'module'
});
worker.postMessage({ targetFile: file, baseChunkSize });
worker.onmessage = async (e) => {
const { chunkList, fileHash } = e.data;
};
}
|
self.onmessage = async (e) => {
const { targetFile, baseChunkSize } = e.data;
const { chunkList, fileHash } = await sliceFile(targetFile, baseChunkSize);
self.postMessage({ chunkList, fileHash });
};
|
5.2 Hash 策略优化
对于超大文件,即使在 Worker 中计算 Hash 也会耗时较长。可以采用抽样 Hash 策略:
- 仅 Hash 文件的第一个分片 + 中间分片的首尾 + 最后一个分片

这种策略的缺点是碰撞概率略高,但在大多数业务场景下是可接受的。
5.3 并发控制
使用 Promise.all 并行上传所有分片,但需要注意控制并发数量,避免占用过多资源:
async function uploadWithConcurrency(chunks, concurrency = 3) {
const results = [];
const executing = [];
for (const chunk of chunks) {
const promise = uploadChunk(chunk);
results.push(promise);
if (chunks.length >= concurrency) {
const executingPromise = promise.then(() => {
executing.splice(executing.indexOf(executingPromise), 1);
});
executing.push(executingPromise);
if (executing.length >= concurrency) {
await Promise.race(executing);
}
}
}
return Promise.all(results);
}
|
六、方案对比
6.1 主流上传方案对比
| 方案 |
优点 |
缺点 |
适用场景 |
| 普通上传 |
实现简单 |
大文件易超时、内存占用高 |
小文件(< 10MB) |
| 分片上传 |
支持断点续传、减少内存占用 |
实现复杂、服务器存储分片 |
大文件上传 |
| 秒传 |
重复文件极速上传 |
需要存储文件 Hash |
允许重复上传的场景 |
| Web Worker |
不阻塞主线程 |
增加复杂度 |
超大文件 |
| 抽样 Hash |
计算速度快 |
碰撞概率略高 |
超大文件优化 |
| CDN 加速 |
上传速度快 |
成本较高 |
面向全国用户 |
6.2 方案选择建议
- 小文件(< 10MB):直接使用普通上传即可
- 中等文件(10MB - 100MB):分片上传 + 断点续传
- 大文件(> 100MB):分片上传 + 断点续传 + 秒传 + Web Worker
- 超大文件(> 1GB):分片上传 + 抽样 Hash + 并发控制
6.3 还需要考虑的因素
- 服务器存储:分片上传会产生大量小文件,需要定期清理
- 安全性:防止恶意用户上传超大文件耗尽存储
- 用户体验:进度条显示、错误提示、自动重试
- 网络环境:弱网环境下的上传体验
七、常见问题
7.1 分片大小如何选择
建议分片大小设置为 1MB - 5MB。过小的分片会增加 HTTP 请求次数,过大的分片会影响断点续传的粒度。
7.2 如何保证分片顺序
服务端按分片索引命名文件(如 chunk-1, chunk-2),合并时按索引排序即可保证顺序。
7.3 如何处理上传失败
分片上传支持重试机制,失败的单个分片可以单独重试,不影响其他分片。
7.4 为什么使用 spark-md5
spark-md5 是专门为大规模文件设计的 MD5 库,支持分块计算 Hash,避免一次性加载整个文件到内存。
总结
本文详细讲解了大文件上传的完整解决方案:
- 分片上传:将大文件切割成小块并行上传,提升稳定性
- 断点续传:记录已上传分片,网络中断后可继续上传
- 秒传:通过文件 Hash 判断重复,重复文件直接返回成功
- Web Worker:将计算密集型任务移到后台线程,避免页面卡顿
- 抽样 Hash:对超大文件采用抽样策略,大幅缩短计算时间
在实际项目中,需要根据业务需求选择合适的方案组合。希望本文能帮助你在面试和实际开发中更好地应对大文件上传的场景。
面试简洁版本
以下是面试时可用的精简版回答,建议背诵核心流程和关键点
一句话概括
大文件上传通常采用分片上传 + 断点续传 + 秒传的方案:前端将文件切片并行上传,服务端存储分片,合并成完整文件;通过文件 Hash 标识实现断点续传和秒传。
核心流程(4步)
1. 前端:File.slice() 分片 + spark-md5 计算文件 Hash
2. 前端:发送验证请求,询问服务端文件上传状态
3. 服务端返回状态:
- 文件已存在 → 秒传成功
- 部分分片存在 → 断点续传(只传剩余分片)
- 文件不存在 → 全部上传
4. 所有分片上传完成后,通知服务端合并
|
关键实现
前端分片:
const chunk = file.slice(start, end)
fileReader.readAsArrayBuffer(chunk)
spark.append(chunk)
|
上传请求:
formData.append('chunk', new Blob([chunk]))
formData.append('index', 1)
formData.append('fileHash', 'abc123')
|
后端合并:
files.sort((a, b) => a.index - b.index)
for (const file of files) {
readStream.pipe(writeStream, { end: false })
}
|
常见面试题
Q1:大文件上传如何实现断点续传?
A:核心是记录已上传的分片。每次上传前先问服务端”这个文件传了多少”,服务端返回已上传的分片列表,前端只传剩余的。
Q2:怎么保证文件唯一性(秒传)?
A:用 Hash 算法(如 MD5)计算文件的”指纹”。上传前先问服务端”这个 Hash 的文件有没有”,有就直接返回成功。
Q3:大文件 Hash 计算太慢怎么办?
A:两个方案:1)用 Web Worker 在后台线程计算,不卡主线程;2)用抽样 Hash(只算首+中+尾分片),牺牲一点准确性换速度。
Q4:分片大小怎么选?
A:一般 1-5MB。太小请求太多,太大断点粒度粗。
Q5:上传失败怎么处理?
A:Promise.all 并行上传,失败的单个分片单独重试,不影响其他分片。
Q6:为什么用 spark-md5 不用 crypto-md5?
A:spark-md5 支持分块计算,不会一次性把整个文件加载到内存,更适合大文件。
方案选择建议
| 场景 |
推荐方案 |
| 小文件(<10MB) |
普通上传 |
| 中等文件(10-100MB) |
分片 + 断点续传 |
| 大文件(>100MB) |
分片 + 断点续传 + 秒传 + Web Worker |
| 超大文件(>1GB) |
+ 抽样 Hash + 并发控制 |


