
文章首发于: https://feinterview.poetries.top/blog/ai-agent-zentao-bug-mcp-integration
用一份自建
MCP Server把禅道 bug 流程接入Claude/Cursor/Codex,文章配套完整的分步落地方案:5 分钟跑通最小版本、关键模块代码、Token缓存、多形态 bug 列表回退、截图落档与归档SKILL,照着做就能把团队的禅道 bug 流程接到 AI Agent 上。
在本篇文章中,我们将从浅入深,和大家一起学习以下知识:
- 为什么不要让 AI Agent 直接「裸调」禅道 REST API
- 用
Node.js 18+实现一份纯stdio的MCP Server的完整步骤 - Token 缓存、HTTPS 强约束、相对路径白名单等安全护栏
- 「我的 bug / 产品 bug / 项目集 bug」三种视角的回退策略
- bug 详情里 HTML 描述、内嵌截图、动态时间线的解析与脱敏裁剪
- 配套
SKILL把 bug 上下文按日期 + 经办人沉淀到本地工作目录 - 生产环境上线前的安全 checklist
痛点与解决方案
在一些以禅道(ZenTao)为唯一 bug 平台的团队里,常见的协作节奏是:测试在禅道里提 bug → 开发翻邮件或 IM 提醒 → 进禅道复制描述、下载截图、看历史动态 → 拉本地分支修 → 回禅道点「解决」并写说明。这个流程的核心矛盾不在禅道本身,而在「bug 上下文是网页里的活数据,AI Agent 看不见」:你让 Cursor / Claude 帮你定位代码,它最多看到你贴过来的一段标题,没法读到内嵌截图、字段编辑历史、上一次评审意见。
解决方法是把禅道 RESTful API 包成一份只暴露最小工具集的 MCP Server,加一份配套 SKILL 让 Agent 主动把 bug 落到本地工作底稿。下面会给出一份从 0 到 1 的完整落地步骤,你照着走就能让团队的 AI Agent 接入禅道。
一、整体架构
整套系统是「Agent ↔ MCP Server ↔ 禅道 REST API」三段式:
┌─────────────┐ stdio ┌──────────────────┐ HTTPS ┌────────────────┐ |
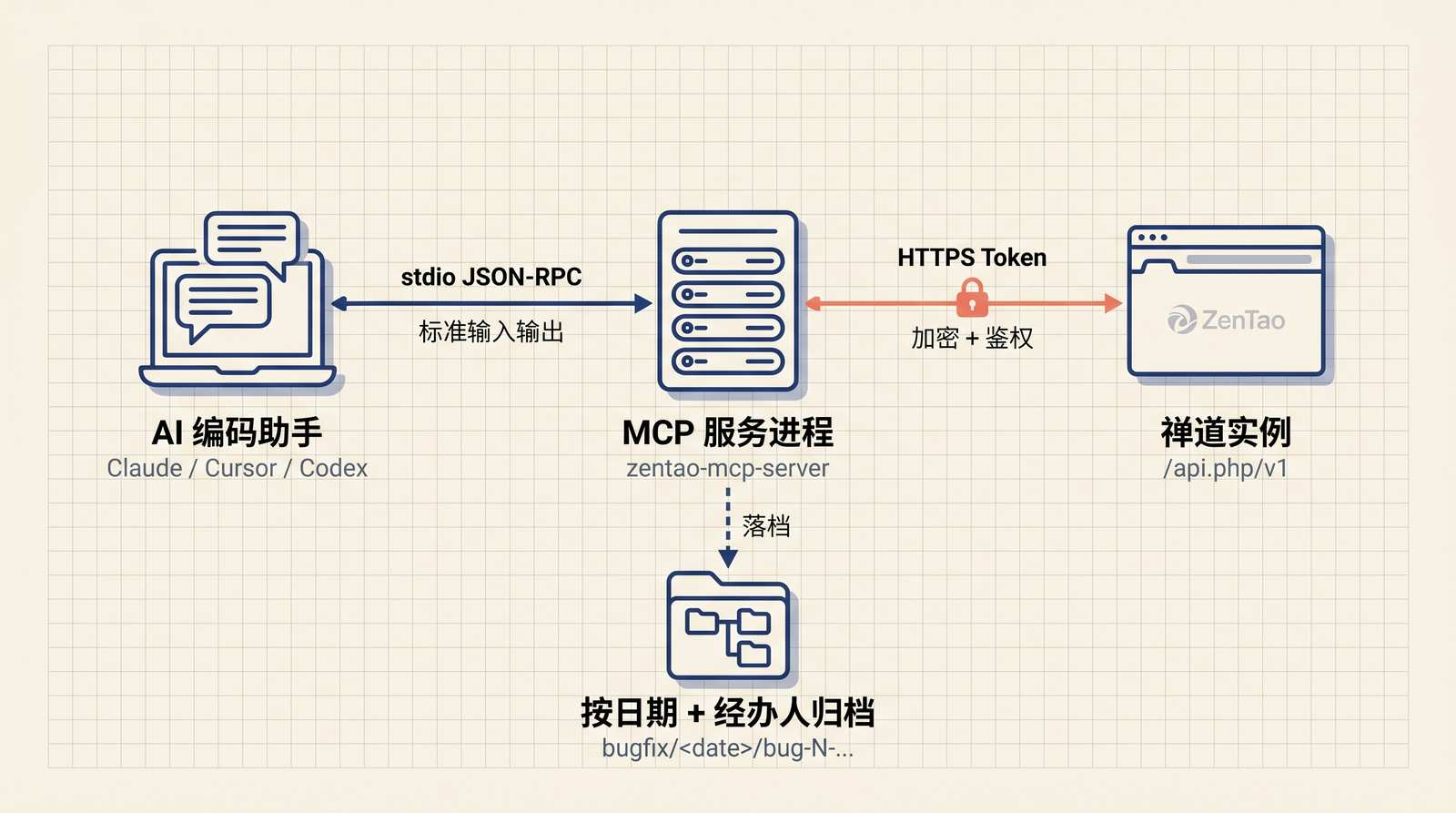
三处选型说明:
- 要求
Node.js 18+:直接用内置fetch+AbortController,省掉node-fetch这类依赖,发布包体积小、攻击面小。 stdio而非HTTP:MCP 客户端把进程 stdin/stdout 接到协议层,Server 不监听端口,省掉鉴权、CORS、TLS 这些自找的麻烦。- 不在仓库里存密钥:所有凭证只从环境变量读,配套
.env.example;连默认日志都做了字段脱敏。
二、五分钟跑通最小可用版本
下面是一份照抄就能跑的最小路径,先把链路打通,再做下一步优化。
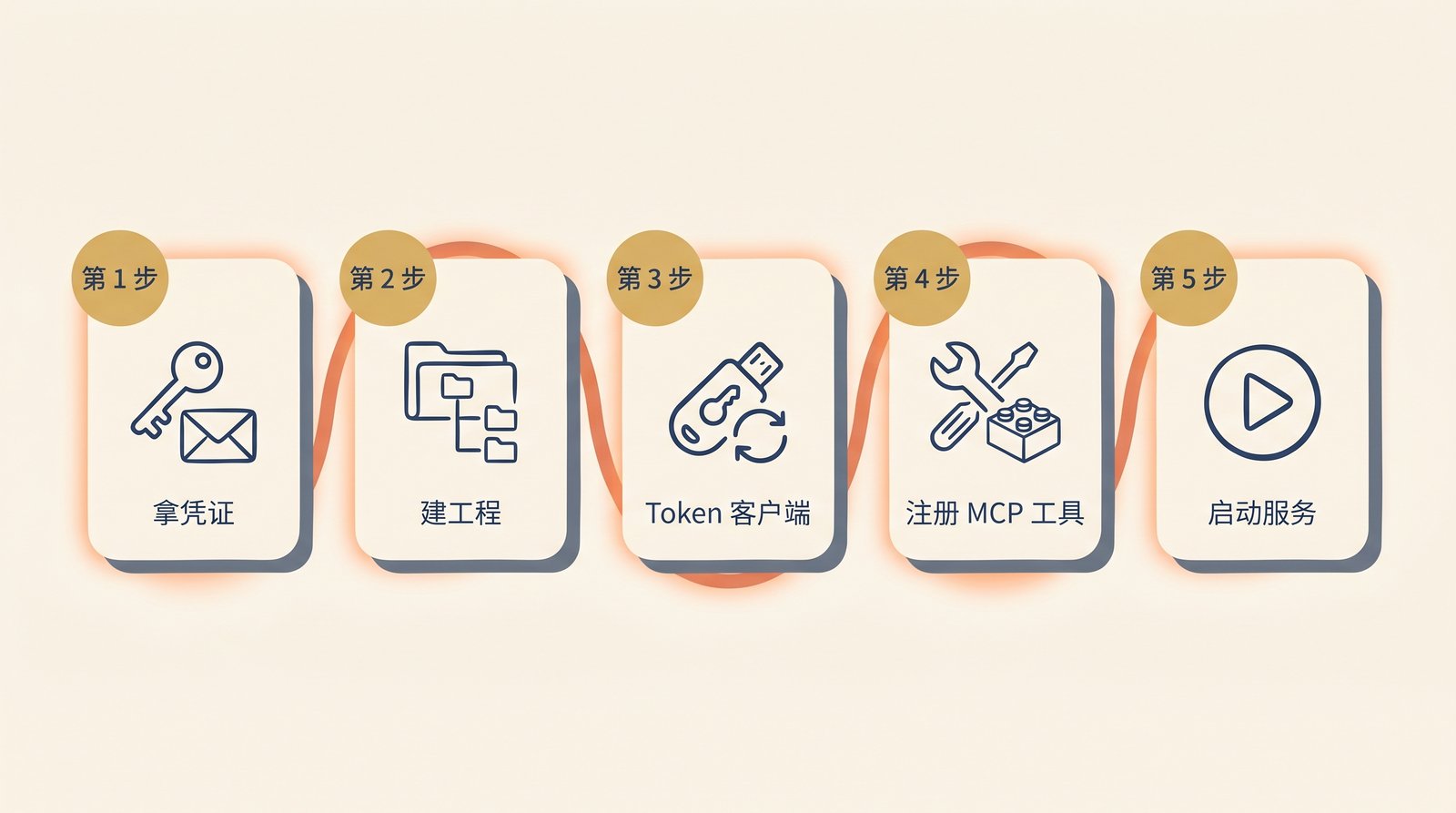
Step 1 准备禅道实例信息
向运维 / DBA 拿到三样东西并验证:
# 1. 禅道访问入口(必须 HTTPS) |
返回里没有 token 字段就先不要往下做,先找运维确认 apiPrefix 是不是 /api.php/v1、是否开启了 RESTful API v1 接口。
Step 2 创建工程骨架
mkdir zentao-mcp-server && cd zentao-mcp-server |
在 package.json 里加上 "type": "module" 和启动脚本:
{ |
Step 3 写一个能拿 Token 的最小 client
新建 src/zentao.js,先把「鉴权 + 请求」这条骨架打通:
export function createZenTaoClient({ baseUrl, account, password }) { |
这里是最小骨架,省略了
AbortController超时、相对路径白名单、HTTPS 校验等安全护栏 —— 第四节会补齐。
Step 4 注册第一个工具
新建 src/index.js,先只暴露一个 get_my_bugs 工具,跑通端到端:
import { Server } from "@modelcontextprotocol/sdk/server/index.js"; |
Step 5 接入 Claude Desktop / Cursor
在 MCP 客户端配置里加这一段(路径换成你自己的):
{ |
重启客户端,跟 Agent 说一句「列出我现在 active 的 bug」,如果能拿到列表,端到端就跑通了。
三、完整工具集设计
最小版本跑通后,再补到生产可用需要 10 个工具,按职责分组:
| 类别 | 工具 | 说明 |
|---|---|---|
| 鉴权 | get_token |
拿/刷新 Token,回显只给脱敏摘要 |
| 探查 | list_my_projects |
列出「我参与的项目」,方便对路径 |
| 读取 | get_my_bugs |
取「指派给我」的 bug,支持产品/项目集 |
| 读取 | get_bug_detail |
单条 bug 详情,含动态时间线 |
| 读取 | get_bug_image |
把 bug 截图按 fileId 拉成 base64 |
| 写入 | resolve_bug |
处理 bug,默认 resolution=fixed |
| 写入 | batch_resolve_my_bugs |
批量处理「我的 bug」,默认遇错即停 |
| 写入 | close_bug |
关闭 bug |
| 写入 | verify_bug |
验证结果:pass=关闭 / fail=激活 |
| 写入 | comment_bug |
添加备注 |
设计要点:
- 读写分离命名:所有动作类工具名是动宾结构(
resolve_bug/close_bug),让模型一眼看出副作用。 - 每个工具都有结构化错误:
{ ok: false, tool, message, status, hint },并在hint里写出最常见的修复建议(比如「报Need product id时设置ZENTAO_PRODUCT_ID」),减少来回试错的轮次。 - 批量动作默认 stopOnError:批量改 bug 是个高危操作,宁可半途停下让用户复核,也不要静默吞错继续跑。
四、Token 与请求层的安全护栏
Step 3 的骨架代码够用但不够安全,上生产前一定要补齐三条硬护栏:
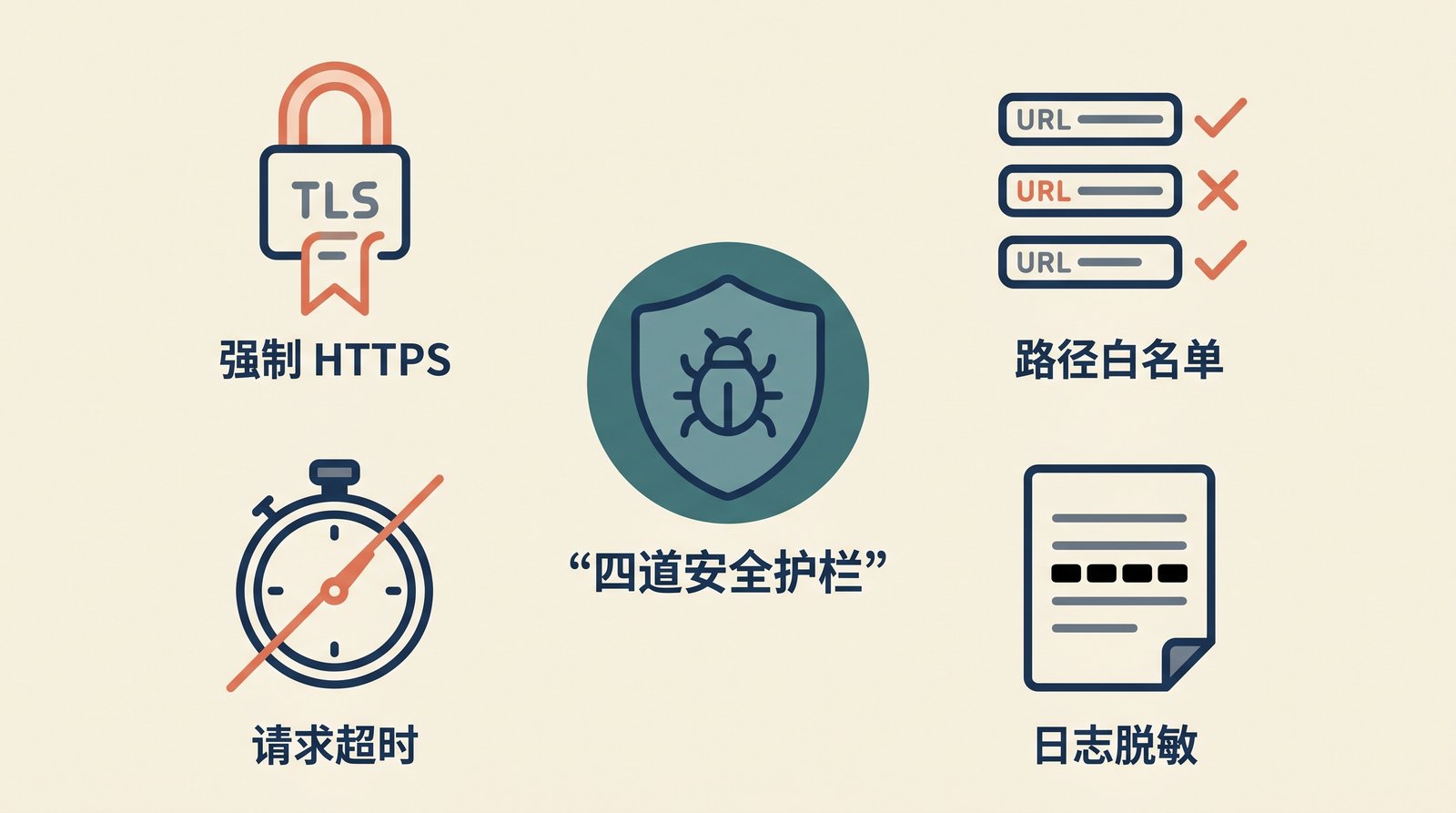
1)默认 HTTPS,不允许裸 HTTP
const parsed = new URL(baseUrl); |
2)相对路径白名单
所有动态 path 都必须过校验,禁止绝对 URL、? / #、%2F / %5C / %2E、.. 段:
function assertSafeRelativePath(value, field) { |
这是为了防止模型把外部 URL 当 path 传进来,把整套 Server 当成 SSRF 代理。
3)请求超时
用 AbortController 给每个请求加超时,避免禅道卡住时 MCP Server 整条挂住:
function createAbortSignal(timeoutMs) { |
4)日志脱敏
ZENTAO_DEBUG=true 打开后,所有工具调用入参会写到 stderr。脱敏在分发层做一道:
const REDACTED = new Set(["body", "query", "comment", "solution", "password", "token"]); |
solution / comment 之所以也算敏感,是因为修复说明经常会带上文件路径、内部接口名、复现账号等细节,团队默认不希望进调试日志里。
五、bug 列表的多形态适配
这是整套实现里最复杂、最有现实价值的一块。原因是:禅道在不同公司被改造得很厉害,同一个「指派给我的 bug」可能挂在三个完全不同的视角下:
- 产品视角(最常见):
/products/{productId}/bugs,需要ZENTAO_PRODUCT_ID。 - 项目集(program/projectset)视角:bug 挂在某个项目集下的项目里,需要
/projectsets/{id}/bugs或/programs/{id}/projects/{pid}/bugs。 - 「我的」视角:直接走
/my/bug//my/bugs,这是部分实例上唯一能命中的入口。
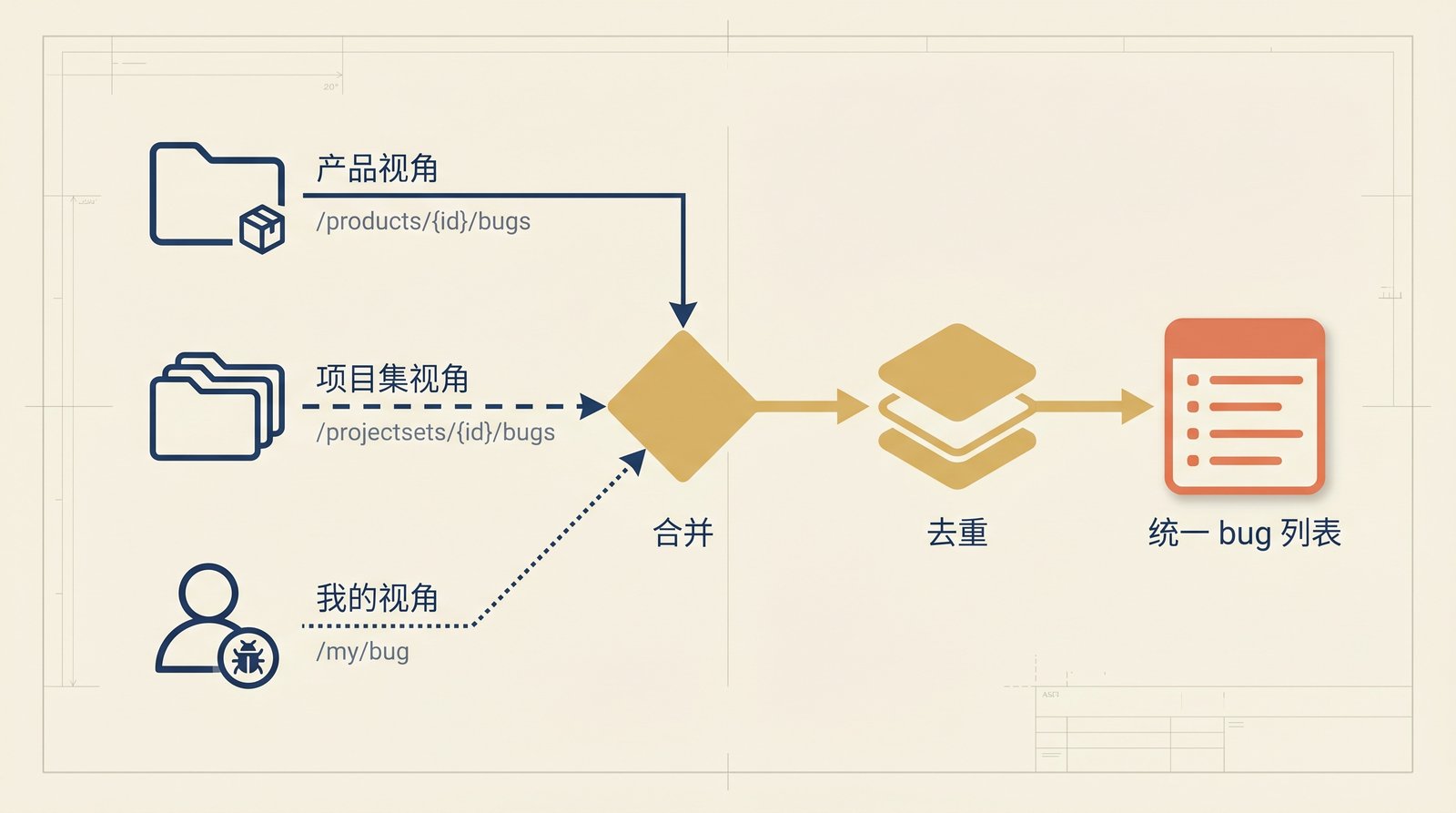
实现策略是「候选路径列表 + 顺序回退 + 合并去重」:
const candidatePaths = []; |
每个候选路径都会被逐个尝试,即使首个路径返回空列表也继续尝试,所有成功的结果再按 bug id 合并去重。同时返回的 raw.triedPaths 里会带上每条路径的 HTTP 状态码和命中数,方便排查「为什么这条 bug 找不到」。
两个细节值得说:
- 「我的 bug」 / 「项目集 bug」端点常常不接受
assignedTo/status/product查询参数,所以这两类路径下 Server 只传limit/page,拿回来后本地再按 assignedTo / status 过滤。 list_my_projects不能作为发现项目集 bug 的唯一入口:有些项目集本身没有创建实际项目,但仍然有「我的 bug」挂在上面,这类数据不会出现在项目列表里。Server 因此在项目集 ID 已知时优先直接打项目集 bug 路径,绕过项目列表这一步。
六、bug 详情与图片落档
get_bug_detail 做了五件事:
走固定
/bugs/{id}接口,避免模型乱传 path。响应裁剪成安全字段:通过
buildSafeBugDetail()只保留title/status/severity/pri/openedBy等明确字段,把assignedTo这种「有时是对象、有时是字符串」的字段统一过normalizeUserIdentity()。保留
stepsHtml/commentHtml原始 HTML:因为内嵌的<img src="...fileID=N">是后续抽截图的来源,纯文本版反而丢信息。抽取
imageFileIds[]:从steps+comment+ 每条action.comment里用两条正则扫出fileID=N和/files/N:const patterns = [/fileID=(\d+)/gi, /\/files\/(\d+)/gi];
function extractFileIds(html) {
const ids = new Set();
for (const re of patterns) {
for (const m of String(html || "").matchAll(re)) {
const n = Number(m[1]);
if (Number.isFinite(n) && n > 0) ids.add(n);
}
}
return [...ids];
}同源 URL 白名单:所有外链都过
normalizeResourceUrl(),只放行与ZENTAO_BASE_URL同源的链接,外部图床、第三方 CDN 一律剔除——避免模型被钓鱼链接污染。
图片本身用 get_bug_image({ fileId }) 单独拉。Server 调 /api.php/v1/files/{id} 拿到二进制流,按 maxBytes(默认 2MB、上限 5MB)截断后 base64 返回,并在响应里带上 truncated: true 标志,让客户端知道这张图被截过、需要的话可以传更大的 maxBytes 重拉。
七、状态扭转工具
写操作的语义其实很简单,但参数设计花了功夫:
resolve_bug必传id,默认resolution=fixed,建议solution写清「根因 + 修复思路 + 改动逻辑 + 影响范围」。Server 内部用buildResolutionComment()拼出最终评论:function buildResolutionComment({ solution, comment, resolution }) {
const s = String(solution || "").trim();
if (s) return `解决说明:${s}`;
const c = String(comment || "").trim();
if (c) return c;
return `已处理,resolution=${resolution || "fixed"}`;
}verify_bug实际是close/activate的语义糖:result=pass→ 走close,result=fail→ 走activate,让 QA 流程映射得更自然。batch_resolve_my_bugs默认maxItems=20、硬上限100、stopOnError=true。批量动作必须显式传solution才有意义,避免出现「批量 fixed 但说明为空」这种没法回溯的痕迹。comment_bug在/bugs/{id}/comment失败时只对 404 回退到/bugs/{id}/comments,其他错误直接抛出 —— 避免在 5xx 上瞎重试导致重复评论。
八、配套 SKILL 落档到本地
光有 MCP 工具还不够。如果 Agent 每次都从禅道实时拉,下一次会话就什么都没有了。配套 SKILL 解决这个问题。
落档目录约束
<项目根>/ |
约束按重要度排序:
- 目录命名强约束:
bugfix/(小写、单数)/<YYYY-MM-DD>/bug-<id>-<assignee>,assignee 转小写并把非[a-z0-9_-]替换成_,避免空格 / 中文 / 斜杠落进目录名。 - 只落档 active bug:列表型查询不触发,已 resolved / closed 的也不落,避免归档目录被历史 bug 灌满。
- 同一 bug 重新指派后走新经办人目录:
bug-1024-frontend_a/bug-1024-frontend_b可同日并存,保留交接痕迹。 - HTML → Markdown 的关键替换:
<img src="...fileID=N">全部替换为本地./images/file-N.png,其它富文本剥成纯文本 + Markdown。 bugfix/默认进.gitignore:里面含内部截图,不入库;需要分享某条 bug 上下文时单独通过 IM 传那一份目录。
在项目里启用 SKILL 的步骤
# 1. 在项目根创建 SKILL 目录(Claude Code 会自动加载) |
SKILL.md 的核心就是把上面的目录约束 + index.md 模板 + action 字段翻译表落成 Markdown,让 Agent 每次调 get_bug_detail 时都按同一模板归档。具体模板可以直接抄本节的目录结构 + 第六节的字段裁剪。
九、上生产前的安全 checklist
在把 MCP Server 推给团队用之前,对照这份清单挨条检查:
- 使用最小权限账号:只授权要访问的产品 / 项目集,不要复用管理员账号
-
ZENTAO_BASE_URL必须 HTTPS,不开ZENTAO_ALLOW_INSECURE_HTTP -
.env不进 git:本地用.env.example占位,凭证从密钥管理(1Password / Vault)下发 - 凭证不进 Agent 上下文:MCP Server 进程内存里持有 Token,不要把 Token 回显给模型
- 写操作必须
resolve/close/verify/comment四个语义工具,不允许通用POST接口 - 批量动作默认
stopOnError=true,maxItems不超过 100 - 路径全部走白名单 + 相对路径校验,禁止 SSRF
- 图片按同源白名单 +
maxBytes截断,外部链接全部剔除 - 日志默认关闭,开
ZENTAO_DEBUG=true时所有敏感字段写<redacted> - 配套 SKILL 的
bugfix/目录在.gitignore,不让内部截图意外推到远端
总结
把禅道接入 AI Agent 的本质,不是「让 Agent 能调禅道 API」,而是「把 bug 流程的上下文从禅道网页搬到 Agent 可操作的工具表和本地工作目录里」。落地分四步走:先用 MCP SDK 跑一个最小可用版本(5 分钟);补齐 Token 缓存、相对路径白名单、HTTPS 强约束、日志脱敏四道护栏(半天);做多形态 bug 列表回退与图片同源裁剪(1 天);最后接配套归档 SKILL(半天)。
这套实现里最值得复用的几个决策:
- MCP 是边界:所有禅道操作都通过 10 个明确语义的工具暴露,凭证不进上下文,写操作必须显式参数。
- 路径多形态回退:不要假设禅道只有一种形态;候选路径 + 顺序回退 + 合并去重,是适配不同部署的现实办法。
- HTML 解析要保留原始结构:纯文本会丢截图,但内嵌 URL 必须过同源白名单。
- SKILL 把瞬时数据沉淀成可追溯档案:bug 上下文按日期 + 经办人归档,比让 Agent「记住」靠谱得多。
当 AI 越来越多承担「读 bug、定位代码、写修复」的工作时,bug 平台一定是最值得早做集成的外部系统之一。一份控制得当的 MCP Server + 一份硬约束的归档 SKILL,就是这一步最小可行的工程化方案。

